自動編碼器
AutoEncoder
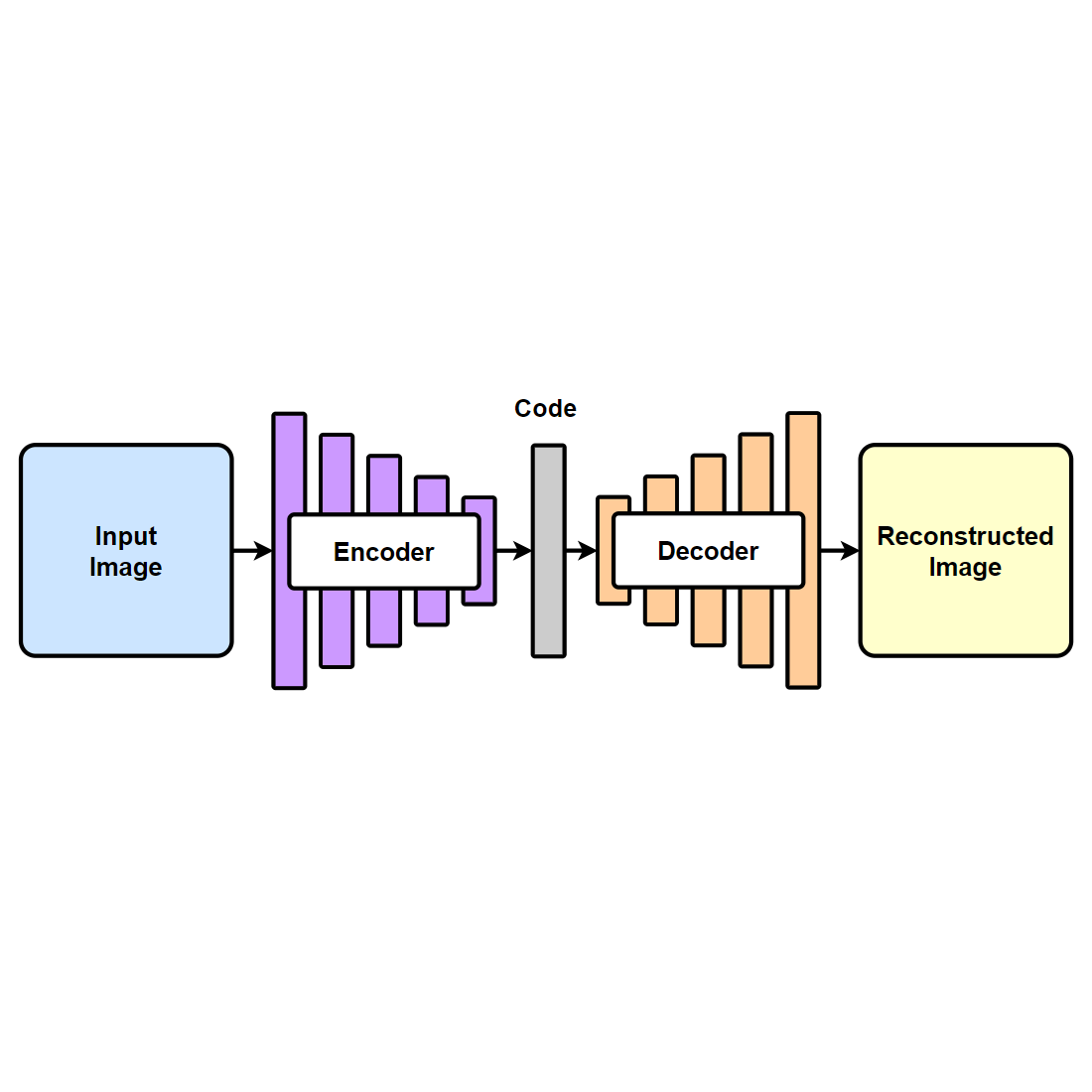
AutoEncoder 是多層神經網絡的一種非監督式學習算法,稱為自動編碼器。
其架構包含 Encoder(編碼器)和 Decoder(解碼器)兩個部分,它們分別做壓縮與解壓縮的動作,讓輸出值和輸入值表示相同意義
透過重建輸入的神經網路訓練過程,
隱藏層的向量具有降維的作用。
特點是編碼器會建立一個或多個隱藏層,
其中包含了輸入資訊的低維向量。
然後再經由解碼器,通過隱藏層的低維向量重建輸入資料。
通過神經網路的訓練最後 AutoEncoder 會在隱藏層中得到一個代表輸入資料的低維向量。
變分自動編碼器
Variational Autoencoder
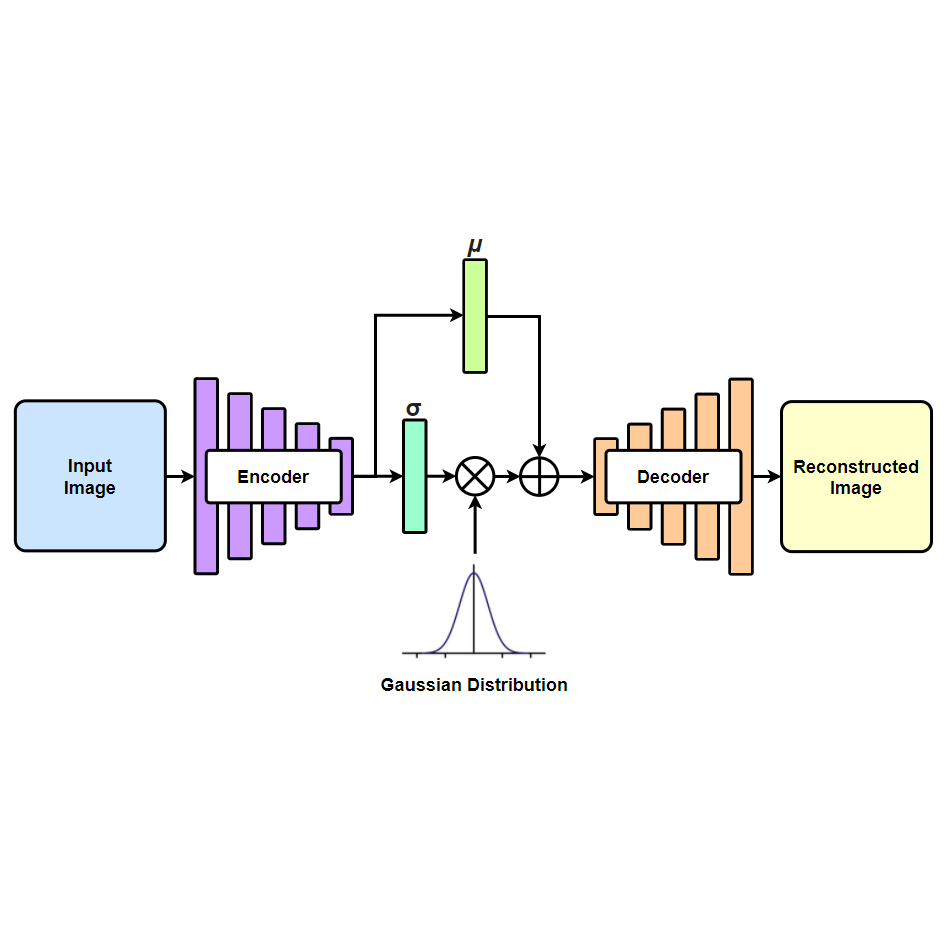
VAE 是由 AutoEncoder 改編而成,結構上也是由 Encoder 和 Decoder 所構成。
Variational Autoencoder 與 AutoEncoder 的不同之處在於 VAE 在編碼過程增加了一些限制,
迫使生成的向量遵從高斯分佈。
由於高斯分佈可以通過其 mean 和 standard deviation 進行參數化,
因此 VAE 理論上是可以讓你控制要生成的圖片。
向量化變分自動編碼器
Vector-Quantized Variational AutoEncoder
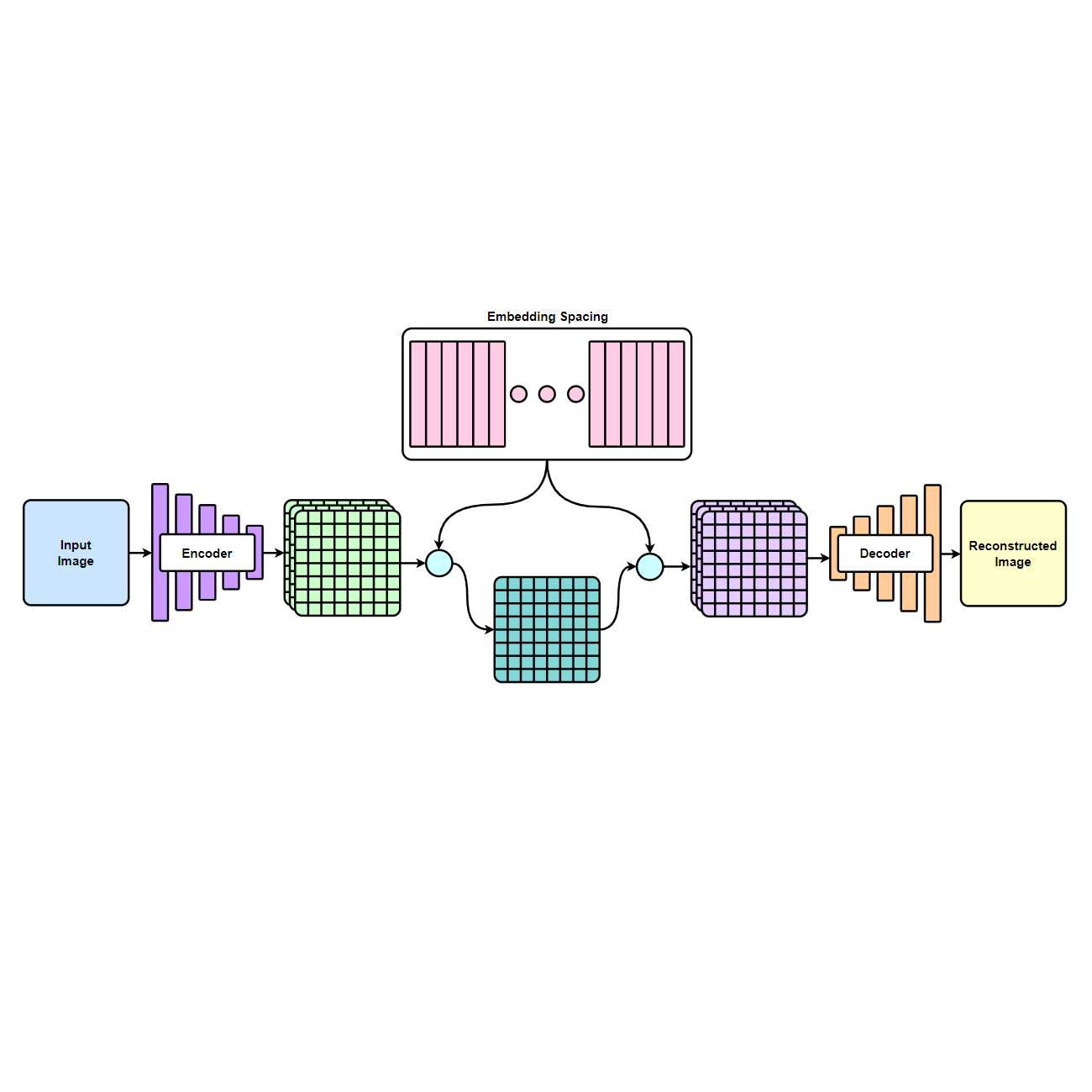
VQVAE 同樣維持著 Encoder-Decoder 的架構,
這邊所提取的特徵保留了多維的結構,
Encoder 的輸出其實就是在 CNN 中我們熟知的 Feature map。
接著在 Vector Quantization 部分會有 K 個編碼向量,
每一個編碼向量同樣有 D 個維度,
根據 Feature Map 中的每個點位比對 D 維的特徵向量與 Codebook 中 K 個編碼向量的相似程度,
並且以最接近的編碼向量索引作取代,
這樣就達到了將原圖轉換為離散表徵的步驟。
在 Decode 階段,
只要將 Codebook 中相對應的編碼向量置於表徵的相對應位置,
就可以得到轉換後的表徵,
接著同樣通過 Decoder 後就可得到還原後的原始資料。