While self-attention excels at modeling global information, it is less effective at capturing high frequencies (e.g., edges etc.) that deliver local information primarily, which is crucial for SISR. To tackle this, we propose a global-local awareness network (GLA-Net) to effectively capture global and local information to learn comprehensive features with low- and high-frequency information.
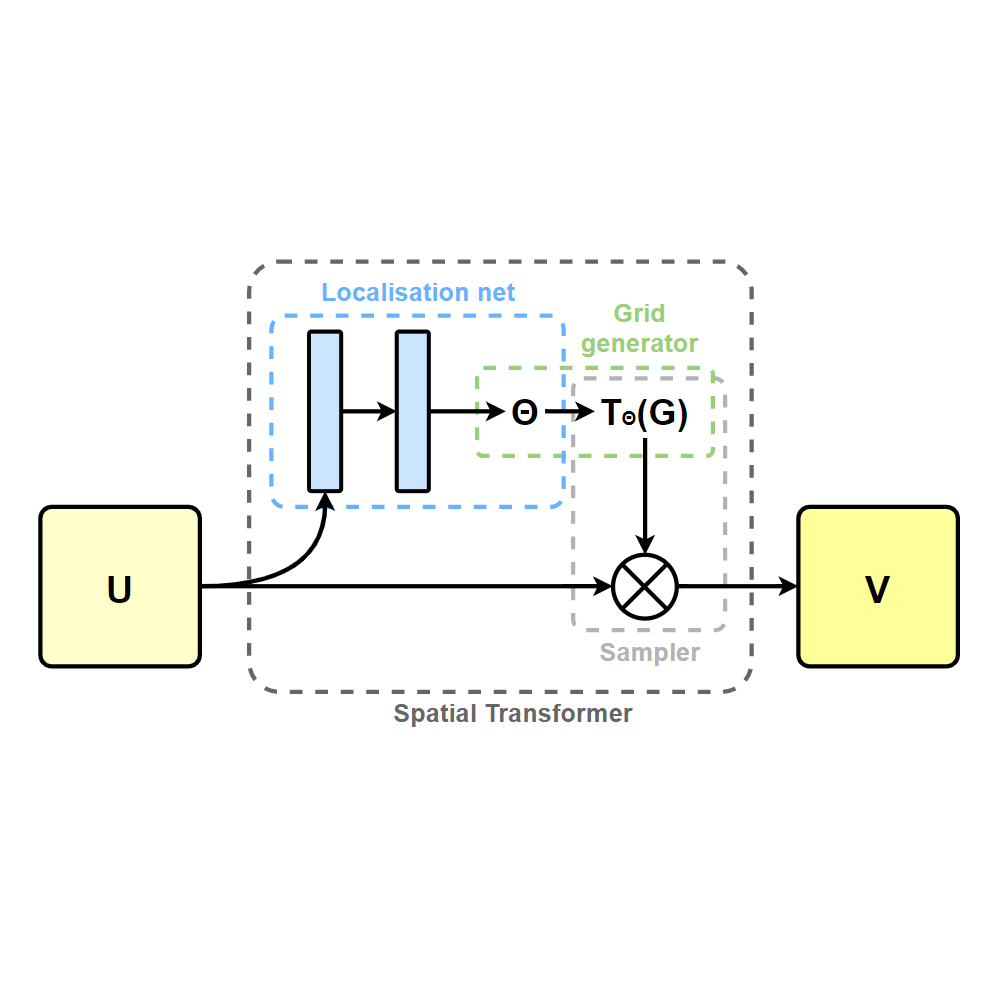
Designing a logo entails a protracted and intricate process for any designer. This research endeavors to introduce a novel architecture of generative adversarial network aimed at producing multimodal logos. Our focus lies in enhancing the model performance of compositional generative adversarial networks by integrating them with spatial transformation networks.
In this research, we propose an appearance-based method for predicting head pose and eye gaze. Furthermore, we leverage decision trees in machine learning to accurately predict the user's viewing area on the screen. This study addresses the challenge of gaze prediction errors arising from variations in head posture, particularly when employing non-wearable devices for gaze prediction.


.jpg)
.jpg)
.jpg)
.jpg)







.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)